
미국의 저널리스트인 대럴 허프는 "통계 용어를 올바르게 이해하고 정직하게 사용하는 발표자와, 사용된 용어의 뜻을 올바르게 이해할 수 있는 대중들이 함께 하지 않는다면 그 결과는 황당한 말장난에 불과"하다고 말한다. 그래서 그는 "새빨간 거짓말, 통계"란 책에서 통계 수치를 그대로 믿으면 안된다고 말한다. 표본의 크기, 비율에 따라 통계 결과가 달라지기도 하고, 산술평균값, 중앙값, 최빈값 등 어떤 평균을 사용하느냐에 따라 의미가 달라지기도 하고, 그래프 축의 간격만 바꿔도 시각적으로 전혀 다른 모습을 보여줄 수도 있기 때문이다. 이러한 통계 조작에 속지 않으려면 다음의 5가지 질문으로 통계 자료를 찔러봐야 한다고 저자는 말한다. 1. "누가 발표했는가?" 즉 통계의 출처를 살펴봐야 한다. 통계를 사용하는..
 통계적 가설 검정(Statistical Hypothesis Testing) 절차
통계적 가설 검정(Statistical Hypothesis Testing) 절차
통계적 가설 검정은 통계적 추측의 하나이다. 전체 집단의 실제 값이 얼마라는 주장에 대해서 표본을 활용해 가설의 합당성 여부를 판단하는 것이다. 빅데이터 시대에는 전체 데이터 대상으로 수집, 처리하기 때문에 통계적 가설 검정이 필요하지 않다. 그러나 전체 데이터를 수집할 수 없다면, 통계적으로 가설이 적합한지를 결정하기 위해 반드시 필요한 절차다. 통계적 가설 검정 절차 통계적 가설 검정은 다음 5가지 절차를 거쳐서 수행한다. 1. 유의수준의 결정, 귀무가설과 대립가설 설정2. 검정통계량 결정3. 기각역의 설정4. 검정통계량 계산5. 통계적인 의사결정 유의수준의 결정, 귀무가설과 대립가설 설정 유의수준(Significance level)이란 통계적 가설 검정에서 사용하는 기준값으로 로 표시한다. 여론조사..
 순열과 조합
순열과 조합
기본적인 배열을 나타내는 순열과 조합에 대해서 간단히 살펴보도록 하죠. 배열 n개의 사물을 배열하는 가능한 방법의 수를 찾으려고 하면 Factorial을 이용하면 됩니다. Factorial은 1808년 수학자 Christian Kramp가 처음 썼다고 하는데요.. n부터 1까지의 수를 모두 곱하는 것이죠. 다른 형식으로는 다음과 같이 사용할 수 있습니다. 파이는 곱을 의미하니 한번 기억해 두면 좋을 듯 합니다. 프로그래밍을 처음 배울 때 재귀함수 호출하면서 Factorial에 대해서 한번씩 구현해 본 기억이 있을 겁니다. 만약 n개의 사물이 원형으로 배열되어 있다면, (n-1)!의 배열이 존재하겠죠.. 추가로 n개의 사물을 배열하려고 할 때, 그 안에 j개의 사물이 하나의 종류이고, k개의 사물이 또 다..
 이산확률분포 #2 - 선형변환과 독립관측
이산확률분포 #2 - 선형변환과 독립관측
지난번에 이산확률분포에 대한 개념과 기대치, 분산을 구하는 방법에 대해서 정리해 봤습니다. 이어서 이산확률분포에서 사용할 수 있는 선형변환과 독립관측에 대해 살펴보기로 하겠습니다. 선형변환기대치를 구할 때 슬롯머신을 예로 들었는데요. 만약 슬롯머신이 게임당 1불에서 2불로 오르고. 당첨금도 5배가 올랐다고 생각해 보죠.. 이 경우, 기대치를 구하기 위해서는 각 수익에 대한 확률분포를 만들고 다음 공식을 사용하면 됩니다. 혹시 처음본다고 느끼시는 분은 이산확률분포#1 - 기대 수준을 관리 글을 다시 읽어 보시기 바랍니다. ^^ X를 Y로만 바꾼 겁니다. ㅠㅠ 그런데 우리는 이미 기존의 수익 X와 기대치 E(X), 그리고 분산 Var(X)까지 값을 알고 있습니다. 처음부터 하나씩 계산하지 않고 이런 정보를 ..
 이산확률분포 #1 - 기대 수준을 관리
이산확률분포 #1 - 기대 수준을 관리
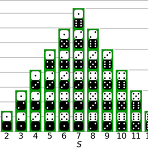
확률분포위키피디아에 따르면 확률분포를 다음과 같이 정의하고 있습니다.확률분포(probability distribution)는 확률변수가 특정한 값을 가질 확률을 나타내는 함수를 의미한다. 주사위를 던질거나 슬롯머신을 할 때 나올 수 있는 모든 가능성의 확률을 모아놓은 집합이 확률분포라고 할 수 있습니다. 다음 그림을 보면 주사위 두개를 던졌을 때 나올 수 있는 두 주사위의 합을 확률분포로 나타내고 있네요. 그러면 이를 수식으로는 어떻게 표현할까요? 정의를 다시 보면 "확률변수가 특정한 값을 가질 확률..." 이라고 되어 있습니다. 확률변수는 일반적으로 X나 Y와 같이 대문자로 표기합니다. 그리고 변수가 가질 수 있는 특정한 값은 x나 y처럼 소문자로 나타내죠.. 변수 X가 특정한 값 x를 가질 확률을 위..
 확률 - 일어날 가능성을 측정하는 방법
확률 - 일어날 가능성을 측정하는 방법
확률(Probability)확률을 왜 배워야 할까요? 확률은 어떤 일이 발생할 가능성을 측정함으로써 미래를 예측할 수 있도록 합니다. 이렇게 어떤 일이 일어날 가능성을 미리 파악함으로써 실제 정보를 바탕으로 의사 결정을 내릴 수 있도록 도와줄 수 있습니다. 그렇다면 확률은 어떻게 구하게 될까요? 확률은 0과 1사이의 값을 갖게 되는데요. A라는 사건이 일어날 확률을 구하는 방식은 다음과 같습니다. 여기에서 n(S)는 전체 경우의 수이고 n(A)는 사건 A가 일어날 수 있는 경우의 수를 나타냅니다. 그렇다면 만약 사건 A가 일어나지 않을 확률은 어떻게 구할까요? 이것을 A'라고 표시하고 사건 A에 대한 여사건(complementary event)라고 합니다. 사건 A가 일어날 확률과 사건 A가 일어나지 않..
 변이와 분포 - 분산과 표준편차
변이와 분포 - 분산과 표준편차
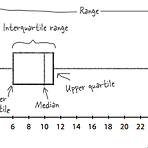
통계에서 분산이나 표준편차라는 말은 많이 들어봤고 수식도 외워봤지만 이것을 왜 써야 하는지는 모르고 배웠던 것 같습니다. 그래서 이번에는 분산과 표준편차를 중심으로 변이와 분포에 대해서 정리해 보려고 합니다. 범위앞서 평균과 관련해서 평균값, 중앙값, 최빈값을 정리했습니다. 만약 여러 사람의 데이터를 비교하려고 하는데 평균이 모두 동일한 경우라면, 데이터의 분포를 통해 비교해 볼 수 있을 것입니다. 데이터의 분포를 확인하는 가장 쉬운 방법은 바로 범위(range)입니다. 범위는 가장 큰 값에서 가장 작은 값을 빼면 되므로 쉽게 계산할 수 있습니다. 그러나 범위에서도 이상치가 나타나면 그 값의 폭이 너무 커지게 됩니다. 그래서 사분위수와 같은 것을 사용하기도 하는데요. 다음 그림(box and whiske..
 평균에 대한 정리 (mean, median, mode)
평균에 대한 정리 (mean, median, mode)
평균(average)이란 것은 워낙 많이 사용해서 잘 알고 있다고 생각하기 쉽습니다. 학교 성적의 평균, 제품의 평균 가격 등 실생활에서도 많이 사용하기 때문이죠. 그런데 평균(average)에도 우리가 알고 있는 평균값(mean)이외에도 다른 종류의 평균이 존재합니다. 이에 대해서 간략하게 정리해 보도록 하죠. 평균값(mean) 가장 일반적인 평균값(mean) 계산 공식은 다음과 같습니다. 즉, 모든 수를 더한 다음에 총 개수로 나누면 평균값(mean)이 완성됩니다. 만약 도수가 있다면 다음과 같이 계산하면 됩니다. 각 수에 도수를 곱한 다음에 그 결과를 모두 더하고 도수의 합으로 나누는 것이죠. 그런데, 만약 값이 극단적으로 한쪽으로 치우쳐 있는 경우에 평균값(mean)은 왜곡될 경우가 있습니다. 예..
 통계를 왜 배워야 하는가?
통계를 왜 배워야 하는가?
미분적분, 수치해석, 확률통계~ 고등학교 때부터 대학교 초기까지 배웠던 통계 관련 과목들입니다. 그동안 별로 관심을 가지지 않고 지냈었는데.. 최근 프로젝트와 맞물려서 다시 공부를 해야 겠다는 생각을 했네요. 역시 사람은 뭐든지 필요할 때가 되어야 비로소 진정한 의미를 알고 다시 시작하는 건가 봅니다. ^^ 앞으로 꾸준히 통계 부분에 대해서는 공부를 하면서 가끔 정리해 볼 계획입니다. 제가 뭐 통계학자도 아니고, 수학을 전공한 사람도 아니기에 제가 이해하는 수준에서 나중에 참고할 수 있도록 부담없이 정리하려고 합니다. 혹시 제가 잘못 이해하고 있는 것을 본 전문가들은 가감없이 댓글 달아주시면 좋겠습니다. 통계의 중요성먼저 통계가 무엇인지부터 정리를 해야 할 것 같네요. Head First Statisti..
- Total
- Today
- Yesterday
- 프로젝트
- HTML
- 맥
- 구글
- 분석
- 아이폰
- XML
- java
- r
- 도서
- fingra.ph
- 자바
- 자바스크립트
- 클라우드
- ms
- 애플
- SCORM
- 통계
- 마케팅
- 웹
- 책
- 세미나
- 하둡
- 빅데이터
- mysql
- 디자인
- 안드로이드
- Hadoop
- 모바일
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |