기계학습이란?
Christoper M. Bishop이 쓴 "Pattern Recognition and Machine Learning" 이란 책을 스터디하고 있습니다.
기계학습(Machine Learning)을 배워보기 위해서 살펴보고 있는데요.
책이 재미있으면서도 조금은 난이도가 있네요.

기계학습이란?
기계학습은 컴퓨터가 학습할 수 있도록 알고리즘과 기술을 개발하는 분야를 의미합니다.
이를 통해 다양한 패턴 인식이나 예측등을 수행할 수 있겠죠.
기계학습을 하기위해서는 수학적 배경 지식들이 중요한데요.
이 책에서도 1장에서 베이즈확률(Bayesian probabilities)와 함께 정규분포를 다룬 Gaussian Distribution 등 여러가지 이야기들이 나오고 있습니다.
앞으로 계속 하나씩 정리해 보도록 하죠.
먼저 관련 용어부터 가볍게 이야기 해보죠.
"training set"은 기계학습을 위한 데이터라고 생각하면 됩니다.
보통 과거의 데이터들이 축적되어 있으면 이 데이터를 기반으로 훈련을 해서 패턴을 인식하게 되는 것이죠.
이러한 데이터를 training set이라고 하는데요.
기계학습에서는 어떤 알고리즘도 데이터의 양을 이길 수 없다고 합니다.
그만큼 훈련할 수 있는 데이터의 양이 중요하다는 것이겠죠. 그래서 요즘 빅데이터에 관심이 많은가 봅니다. ^^
이어서 "target vector" 즉, t라고 하는 것이 있는데요.
실제 결과값이라고 보시면 됩니다.
만약 사람이 손으로 쓴 숫자를 인식한다고 하면 미리 알고 있는 결과값이 t가 되겠죠.
기존의 사람들의 손글씨를 training set으로 보고 훈련해서 나오는 예측값과 결과값 t가 최대한 일치하게 만드는 것이 바로 기계학습이라고 보면 됩니다.
기계학습의 종류
Supervised learning
Supervised learning은 training set으로 부터 하나의 함수를 유추해 내기 위한 기계학습의 한방법인데요.
입력 값에 대한 결과값, 즉 target vector가 무엇인지 미리 알고 있는 경우라고 합니다.
즉 "training set"과 "target vector"를 모두 알고 있는 경우를 말하는 것이죠.
이 중에서도 주어진 입력 값이 어떤 종류의 값인지 표시하는 것을 "Classification"이라고 하구요.
유추된 함수에서 연속적인 값을 출력하는 것을 "Regression"이라고 합니다.
Unsupervised learning
unsupervised learning은 입력값에 대한 결과값, 즉 target vector가 주어져 있지 않은 경우입니다.
그러므로 데이터가 어떻게 군집되었는지 모르기 때문에 이러한 구성을 알아내는 문제를 해결하기 위한 기계학습이라고 할 수 있습니다.
그래서 unsupervised learning은 밀도를 측정하고 시각화하는 것과 연관을 가지고 있습니다.
주로 비슷한 범주끼리 묶어주는 역할을 하는 "Clustering"이 unsupervised learning의 하나라고 할 수 있습니다.
Reinforcement learning
보통 good dog, bad dog으로 이야기를 많이 하는데요.
어떤 환경을 탐색하는 에이전트가 현재의 상태를 인식해서 어떤 행동을 했을 때, 보상을 얻게 되는 것을 의미합니다.
그래서 보상을 최대화하는 행동으로 정의되는 정책을 찾는 것이라고 할 수 있습니다.
강아지가 훈련을 잘 따라오면 먹이를 보상으로 주는 것과 비슷해서 good dog/bad dog이라는 사례를 많이 드는 것 같습니다.
간단한 사례
정의만 하고 마무리 하면 아쉬우니 Polynominal curve fitting이라고 하는 다항식 관련 예제를 정리하도록 할께요.
먼저 training set인 X가 다음과 같이 N개 주어져 있다고 가정해 보죠.

여기에서 T는 column vector를 의미합니다.
만약 T가 없다면 행렬에서 이야기하는 row vector가 되겠죠.
그리고 X에 대응하는 target vector인 t를 다음과 같이 나타냅니다.
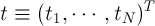
이럴때 X들을 잘 연결해서 하나의 곡선을 만들어 주는 것이 바로 curve fitting 입니다.
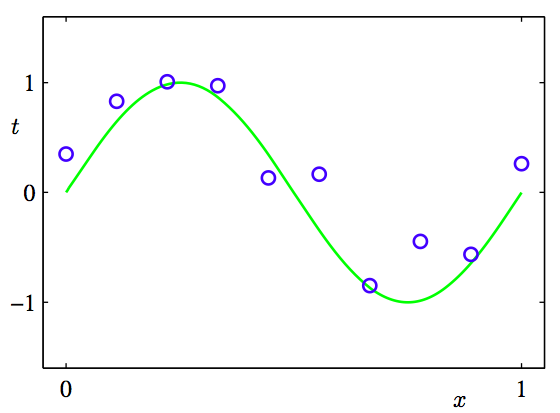
그리고 입력값 X에 대한 이러한 함수를 만들어 보니 다항식이 된다는 것이죠.
(예제 그림에서는 sin 함수로 나오네요)

여기에서 M은 바로 다항식의 차수가 되겠죠.
위 식에서 w값인 weight만 잘 계산하면 실제 결과와 근사치가 가능하다는 것입니다.
이런 경우, w를 최소화 하는 것이 중요하므로 이를 활용해 error function을 만들어 볼 수 있다고 하네요.
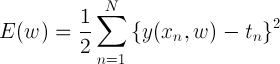
마치 분산이나 표준편차를 계산하듯 실제 결과값인 target vector에서의 예측치의 거리를 계산하고 있는 것을 알 수 있습니다.
2로 나눈 것은 나중에 계산이 편리하기 때문이라고 합니다.
x, w, t를 제외한 나머지 변수인 M과 N에 대해서 잠깐 설명하면
M은 다항식의 차수를 이야기 하는데요.
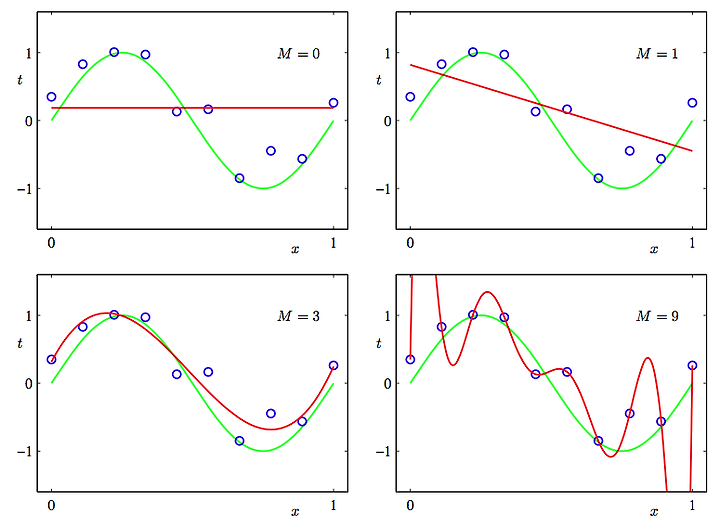
너무 클 경우, overfitting이라고 해서 오히려 안좋은 결과가 나올 수 있다고 합니다.
다음 그림과 같이 M=9일때, 더 이상한 곡선이 나오고 M=3일때 원하는 곡선이 나오는 것을 알 수 있습니다.
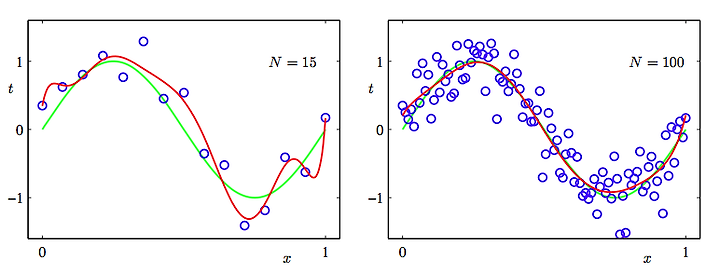
N은 training set 의 개수를 이야기 하는데요.
앞서 언급한 것처럼 데이터 양이 많을수록 좋은 결과를 얻게 됨을 이 그림으로도 알 수 있을 겁니다. ^^
앞으로 기계학습도 꾸준이 올려보도록 하겠습니다.
다음에는 기계학습에서 주로 사용하는 확률 이론에 대해서 정리해 보도록 하죠.