베이즈 확률(Bayesian Probabilities)과 가우스 분포(Gaussian Distribution)
확률에서 많이 사용하는 베이즈 정리는 "확률 - 일어날 가능성을 측정하는 방법"의 끝부분에도 간략하게 정리했었습니다.
이번에는 베이즈 정리를 좀 더 깊이있게 알아보도록 하죠.
베이즈 확률 (Bayesian Probabilities)
실생활에서 베이즈 정리는 스펨 메일 필터링이나 유전자 검사 등에서 활용한다고 했습니다.
기계학습에서도 이런 베이즈 정리를 많이 사용하는데요.
이전의 기계학습 예제를 설명할 때, Training Set에서 주어진 X에 대해 적절한 곡선을 만들어 주는 것을 Curve fitting이라고 했었습니다.
이러한 Curve fitting을 하는 방법이 보통 두가지가 있는데요.
하나는 Frequentist treatment이고 나머지 하나가 Bayesian treatment입니다.
여기에서 Frequentist는 주어진 데이터의 양, 즉 Training Set이 적을 경우에 오류 가능성이 매우 높습니다.
그래서 복잡하기는 하지만 데이터 양이 적거나 반복해서 테스트할 수 없는 경우에 베이즈 정리를 사용하게 됩니다.
Curve fitting을 사용한 예제에 대해서는 다음에 한번 더 정리해 보도록 하죠.
베이즈 확률은 보통 다음과 같이 정의합니다.
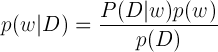
D가 주어졌을 때 w가 나올 조건부 확률을 위와 같이 계산하는 것을 바로 베이즈 확률이라고 합니다.
여기에서 posterior와 prior, 그리고 likelihood와 같은 용어를 사용하는데요.
해당 용어를 사용해서 Bayesian을 정의해보면 다음과 같습니다.
뒤사건이 발생할 확률(posterior probability)는 앞사건이 발생했던 확률(prior probability)에 어떤 값(likelihood function)을 곱해서 나온다.
위 정의를 기반으로 기본적인 Bayesian Probability의 각 값들을 posterior, prior, likelihood와 매핑하면 다음과 같습니다.


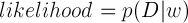

앞서 이야기한 Frequentist나 Bayesian 모두 위 식에서 사용한 likelihood function인 p(D|w)가 매우 중요한 역할을 합니다.
Frequentist Treatment에서는 p(D|w) 즉 likelihood function이 최대가 되는 값을 구하면 문제가 해결된다고 합니다.
이를 Maximum likelihood 라고 하며, error function은 likelihood function에 negative log 를 취하면 된다고 합니다.
다만 미리 수행한 데이터를 기반으로 결정을 한다는 단점이 있습니다.
예를 들어, 동전을 세번 던졌는데 모두 앞면이 나왔을 때 Frequentist로 계산하면
동전은 항상 앞면이 나오는 것으로 간주하고 Maximum likelihood를 계산하게 됩니다.
이 경우에는 당연히 잘못된 결과가 나오겠죠.
Bayesian Treatment에서는 이를 보완하기 위해서 w를 확률에 따른 값으로 계산하게 됩니다.
즉, prior를 Frequentist와 같이 정해진 값으로 보는 것이 아니고
어떤 값이라도 나올 수 있는 확률로 계산하는 것입니다.
그래서 일반적으로 Bayesian이 Frequentist보다는 복잡하지만 데이터 양이 적을 때 오류가 적다고 이야기 합니다.
가우스 분포(Gaussian Distribution)
가우스 분포는 흔히 이야기하는 정규 분포를 나타냅니다.
다음 그림은 전형적인 정규 분포와 평균, 그리고 분산을 보여주고 있습니다.
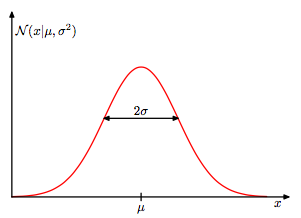
하나의 실제값 x에 대한 정규 분포에 따른 확률은 다음과 같이 나타낸다고 합니다.
여기에서 N은 확률인 P를 의미하는데 정규분포(Normal Distribution)를 알려주기 위해 사용한 것이고,
μ는 평균, 그리고 σ의 제곱은 분산을 나타냅니다.

복잡하네요. 정규분포는 이런 식이 나온다는 것 정도만 알고 있으면 될 것 같습니다.
물론 확률이므로 0보다는 크고, 전체 합은 1이 되겠죠.
위 식은 하나의 변수에 해당하는 것이므로 다차원, 즉 여러 변수로 확장하면
각각의 변수에 따른 확률이 독립이라고 가정할 때, 모두 곱하면 됩니다.
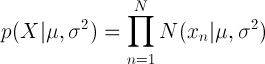
이 식에서 평균과 분산을 구하기 위해 likelihood function을 최대로 하는 값을 계산하면 됩니다.
책에 매우 복잡하게 나와있는데요..
먼저 위 식의 양변에 log를 취하게 되면, 지수식이 없어지게 됩니다.
그리고 나면 μ의 2차 방정식이 되는데요..
이 경우 미분을 해서 0이 되는 값을 구하면 바로 μ에 대한 최대값을 얻게 됩니다.

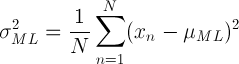
평균에 대한 Maximum likelihood 값이 실제 평균과 일치하는 것을 확인할 수 있을 겁니다.
실제 Maximum likelihood에 대한 기대값을 계산해 보면 다음과 같이 나타나는데요.

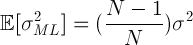
분산의 경우, 실제 분산값과 차이가 있지만 N이 충분히 크다고 가정하면 문제는 없다고 합니다.