Conjugate Prior에 대하여
베이시안(Bayesian) 정리를 살펴보면 다음과 같은 식을 이야기 했었습니다.
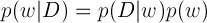

여기서 Posterior 확률을 구하는 것이 문제인데요.
예를 들어, 만약 p(w)를 남편이 바람 필 확률이라고 해보죠.
그리고 p(D)가 셔츠에서 입술자국이 나올 확률이라고 가정해 보겠습니다. (예제가 좀 그런가요? ㅠㅠ)
이때 Posterior인 p(w|D)는 셔츠에서 입술자국이 나왔을 때 바람필 확률이라고 보면 됩니다.
즉, 만약 남편 셔츠를 봤는데 입술자국이 있으면 실제로 바람을 폈을 확률이 어떻게 될지를 예측할 수 있다는 것이죠.
만약 Bayesian으로 Posterior를 계산한다고 할 때, 각 항목이 일반적인 분포를 따르지 않는다고 하면 도출하는 방식이 매우 복잡해질 수 있다는 것입니다.
반대로 likelihood가 특정 분포를 따른다고 가정할 때, Prior와 Posterior가 동일한 분포를 따른다면 계산이 매우 편해진다는 것입니다.
그래서 이렇게 Prior와 Posterior가 쌍을 이룰 수 있도록 맞춘 것이 바로 Conjugate Prior라고 합니다.
이럴 경우, Prior와 likelihood를 곱해서 나온 Posterior가 다시 Prior형식이므로, 보다 쉽게 Posterior의 분포를 확인할 수 있게 됩니다.
Conjugate Prior로 활용할 수 있는 주요 분포는 다음과 같습니다. (http://www.roma1.infn.it/~dagos/rpp/node31.html#tab:conjugates 참고)

책에서도 conjugate prior에 대해서 다음과 같이 이야기 하고 있습니다.
We shall see that an important role is played by conjugate priors, that lead to posterior distributions having the same functional form as the prior, and that therefore lead to a greatly simplified Bayesian analysis.
역시 conjugate prior를 사용하면 Bayesian을 단순화할 수 있다는 의미를 강조하고 있네요.