Binary Variables - 베르누이 분포와 이항 분포에 대하여
Binary Value에 대한 확률 분포는 동전을 던지는 경우를 생각하면 됩니다.
동전의 앞면이나 뒷면이 나오는 것과 같이, 나올 수 있는 경우의 수가 0과 1인 경우를 Binary라고 하죠.
Bernoulli Distribution (베르누이 분포)
이러한 확률 분포는 Bernoulli 정리로 나타낼 수 있습니다.
0 <= u <= 1일 때,

x가 0일때 확률분포가 1-u이고, 1일때는 u라는 생각하면 쉽게 이해가 될 겁니다.
여기에서 확률분포 계산에 따라 기대값과 분산을 계산해보면 다음과 같습니다.


만약 여러번 시도를 할 경우, 독립이기 때문에 확률은 곱해주면 됩니다.
여기에서 D는 x를 처음부터 N번까지의 시도한 것이라고 보면 됩니다.

예전에 설명한 베이즈 정리와 관련된 내용을 생각해보면 likelihood와 같은 형태임을 알 수 있습니다.
이미 수행한 데이터를 기반으로 maximum likelihood를 계산하면 우리가 원하는 N번시도했을 때의 u의 최대값(posterior)을 구할 수 있을 것입니다.
이를 위해 먼저 log likelihood function을 사용하는데요. log를 취해도 최대값을 가지는 x는 그대로 있고 계산하기 편하기 때문인 듯 합니다.

그리고 나서 미분을 해서 0이 되는 값을 구하면 바로 u의 최대값을 구할 수 있겠죠.
이렇게 계산을 하면 u에 대한 maximum 값은 다음과 같이 나오는데요.. 일반적인 평균을 구하는 것과 동일합니다.

그런데 만약 동전을 3번 던져서 모두 1이 나왔다면, N=3이고 Xn의 합도 3이 되어 maximum likelihood 값이 1이 됩니다.
하지만 실제로 동전을 던졌을 때의 평균은 0.5가 되어야 하는데, 잘못 된 예측이 되겠죠.
바로 이부분이 시도 횟수가 적을 때, Frequentist Treatment의 단점입니다.
Binomial Distribution (이항 분포)
이번에는 조금 다른 관점에서 살펴보도록 하죠.
동전을 N번 던졌을 때, 앞면 즉 1이 나올 확률을 계산할 때 Binomial Distribution을 사용합니다.
보통 시도횟수가 정해져 있을 때, 특정 항목이 몇번 나올 확률은 Binomial을 사용하고,
시도횟수가 정해지지 않고, 몇 번의 시도만에 성공할 확률을 구할 때는 Geometric Distribution (기하 분포)를 사용하게 됩니다.
Binomial Distribution의 공식은 다음과 같습니다.

앞의 베르누이 공식과 비슷하지만 조합으로 N번중에서 m번이 발생할 경우를 곱해준다는 차이가 있습니다.

Binomial Distribution에서의 기대값과 분산을 계산하기 위해서는 모두 독립이므로 더해주면 됩니다.


잘 기억해 보면 예전에 이항 분포에서 기대값은 np, 분산은 npq로 외웠던 기억이 있을 거예요. ^^
Beta Distribution (베타 분포)
앞서 베르누이 분포에서 Frequentist Treatment를 사용하여 maximum likelihood를 적은 데이터로 계산할 때, 잘못된 결과가 나올 수 있다는 것을 살펴봤습니다.
이에 대한 해결책은 바로 likelihood 뿐만 아니라 Prior를 확률로 보고 계산하는 Bayesian Treatment입니다.
이럴 경우, 당연히 계산이 더욱 복잡해지게 될 것입니다.
그래서 likelihood가 특정 분포를 따른다고 할 때, prior와 posterior가 동일한 분포를 따를 수 있도록 Conjugate Prior를 사용하는 겁니다.
Binary Variable에서는 likelihood가 Binomial Distribution을 따를 때, Conjugate Prior로 바로 Beta Distribution을 사용합니다.
즉, 이러한 형태가 되는 것이죠..



Beta Distribution에 Binomial Distribution을 곱하면 다시 Beta Distribution이 나온다는 것입니다.
이러한 것이 Conjugate Prior라고 합니다. 그럼 Beta Distribution의 식을 살펴보죠.

감마는 일반적으로 (정수 뿐만 아닌) 모든 수에 대한 팩토리얼 연산을 나타낸다고 합니다.
실제로 Beta는 Binomial과 매우 유사하다는 것을 알 수 있습니다.
여기에서 a와 b는 parameter인 u에 대한 분포를 제어하는 것으로 hyperparameter라고 하는데요.
다음 그림과 같이 a와 b가 커질수록 u에 다가가는 것을 알 수 있습니다.
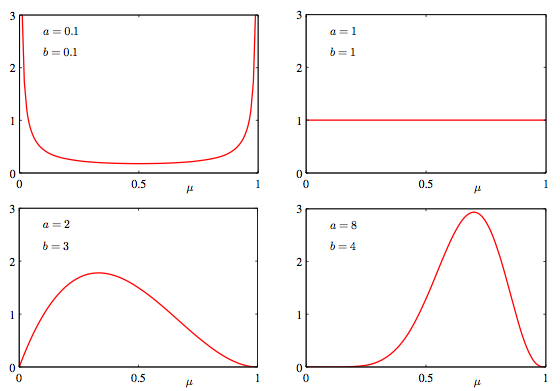
Posterior는 likelihood 와 prior의 곱으로 나타낼 수 있습니다.
Prior는 위 식과 같고 likelihood는 Binomial로서 m, l이라는 파라미터를 가진다고 하면 다음과 같이 Posterior를 나타낼 수 있습니다.

Posterior 역시 Beta Distribution을 따르는 것을 확인할 수 있습니다.
이를 그래프로 살펴보면 다음과 같습니다.

실제로 연속적인 실시간 기계학습 시나리오 중에서 이렇게 반복적으로 수행함으로써 믿고 싶은 사실을 증거를 통해 변경하기도 한다고 합니다.
이와 같이 사용할 때, 반복적으로 수행함으로써 값이 정확해지는지를 검증하기 위해서 분산을 사용합니다.
데이터 집합 D에서 관측한 θ가 있다고 할때, θ의 평균값은 같게 나올지라도
D를 확인하고 살펴본 θ의 분산이 θ의 분산보다 작다면, 범위의 폭이 좁으므로 좀 더 정확해진다고 할 수 있겠죠.

위 수식을 보면 θ의 분산은 D를 조건으로 하는 θ의 분산값의 평균에 다른 값을 더한 것이므로
Var[θ]가 Var[θ|D]보다 크게 나올 것이기 때문에 Beta를 이용해 반복할수록 값이 정확해진다고 합니다.
이상으로 Binary Value에 대한 Bernoulli, Binomial, Beta Distribution을 살펴봤습니다.
0과 1이라는 두가지 경우만을 다루기 때문에 다른 것보다는 이해하기가 쉬운 것 같습니다.
이를 기반으로 multinomial 등으로 확장해 나가기 때문에 그래도 한번 더 정확하게 알아두는게 좋을 것 같네요.