Nonparametric Method - 평균/분산을 모를때 확률분포를 만드는 방법
지금까지 살펴본 확률분포는 모두 평균이나 분산과 같은 매개변수들을 기반으로 확률분포를 정하게 됩니다.
예를 들어, 정규분포(Normal Distribution)에서는 평균과 분산을 알고서 확률분포를 구하게 되죠..
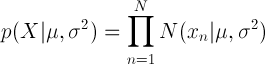
그런데 만약 평균과 분산과 같은 매개변수를 모를 경우, 확률 분포를 어떻게 알 수 있을까요?
특히 정규분포와 달리 여러개의 봉으로 이루어진 데이터라면, 기존의 방식으로 확률 분포를 알수는 없을 겁니다.
이렇게 매개변수가 없을 때, 확률 분포를 구하는 방법을 Nonparamtric Method라고 합니다.
(보통 비모수적 방법이라고 이야기 하는 것 같습니다.)
Nonparametric Method는 보통 Histogram, Kernel Density, Nearest Neighbour 세가지가 있는데요.
각각에 대해서 간략하게 정리해보도록 하겠습니다.
Histogram Density Model
히스토그램은 많이 들어봤을 겁니다.
막대그래프와 달리 각 영역이 붙어 있는 것이 특징인데요.
바로 이 영역의 넓이를 Δ라고 하는데, 이 Δ값에 따라서 확률 분포가 결정되게 됩니다.
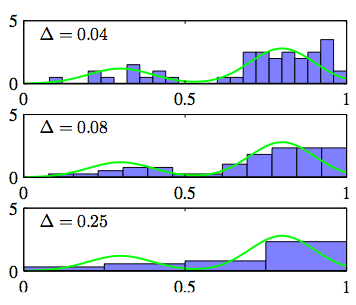
위 그림과 같이 초록색과 같은 데이터 분포에 대해, 히스토그램을 그려보면 Δ값에 따라 다르게 나타나는 것을 알 수 있습니다.
원래 데이터는 봉이 두개인 그래프인데요..
Δ값이 너무 작거나 너무 크면 해당 그래프의 모습을 반영하지 못하고 있습니다.
위 그림에서는 Δ값이 0.08일때, 적절하게 확률 분포를 나타내 주고 있는 것을 알 수 있습니다.
이와같이 적절한 Δ의 값을 결정하는 것은 Histogram Density Model에서는 중요한 부분이라 할 수 있습니다.
하지만 히스토그램은 빠르고 쉽게 그릴 수 있다는 장점이 있지만 다음과 같은 문제점도 가지고 있습니다.
먼저 경계값에 데이터가 몰려 있을 경우, 제대로 확률분포를 만들어 내지 못할 수 있습니다.
그리고 예전에 Curve Fitting에서 Dimension의 저주라고 이야기한 것처럼, 차원이 늘어날 수록 문제가 발생하게 됩니다.
(2013/04/22 - [Cloud&BigData/Machine Learing] - Curve Fitting으로 살펴보는 Frequentest와 Bayesian Treatment)
이러한 문제를 해결하기 위해 Kernel density나 Nearest neighbour 를 사용하게 됩니다.
Kernel Density Estimators
Kernel Density는 히스토그램의 경계 문제를 해결한 것인데요.
어떤 값 x가 R이라고 하는 영역에 들어갈 확률을 P라고 하면 다음과 같이 나타낼 수 있습니다.

이때 전체 N 중에서 K개가 R에 들어갈 확률을 P라고 하면, 앞서 배운 Binomial Distribution이 되고 기대값은 다음과 같이 나타낼 수 있습니다.

만약 N이 상당히 크다고 가정하면 다음과 같이 이야기할 수 있습니다.

또한 전체 확률 P는 개별적인 확률인 p(x)와 R의 볼륨을 V라고 하면 둘의 곱으로 나타낼 수 있습니다.

위 두 식을 결합하면 다음과 같이 p(x)를 나타낼 수 있습니다.

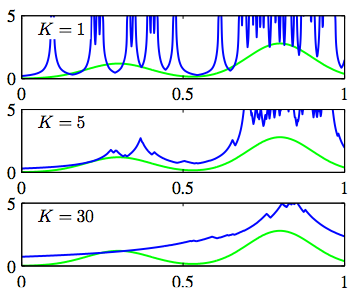
여기에서 K를 고정해놓고 V값을 결정해서 확률분포를 알아내는 것이 K-nearest-neighbour 방식이고,
V를 고정해 놓은 상태에서 K값을 결정해서 확률분포를 만드는 것을 Kernel 방식이라고 합니다.
Kernel 방식에서 K값을 결정하기 위해서 다음과 같은 수식을 사용합니다.
Xn이 X를 중심으로 h라는 큐브 영역에 들어가는지 확인하는 것입니다.
이러한 Kernel function을 Parzen window라고 한다네요..

이 식을 위 p(x)를 구하는 곳에 대입하면 다음과 같습니다.
V를 hD로 표시해서 점 하나가 아닌 전체를 고려한 것이라고 보면 됩니다.

원래 목적이었던 경계값 측면에서 보면 이 식도 h라는 영역에 들어가면 1, 아니면 0이 되므로 약간 보정할 필요가 있습니다.
만약 정규분포와 같은 수식을 활용하면 경계값에 들어가느냐 아니냐를 판단하기 보다 얼마나 가까운지로 결정할 수 있으므로
히스토그램의 경계값 문제를 어느정도 해결한다고 생각해도 됩니다.
정규분포의 수식으로 대체한 것은 너무 복잡하니 생략할 께요.
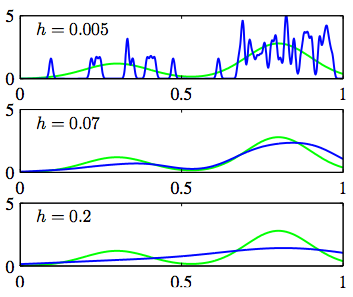
히스토그램이 Δ값에 영향을 받은 것처럼, Kernel 방식도 h 값에 의해 Fitting이 다음과 같이 달라집니다.
Nearest-neighbour methods
이름 그대로 가까운 것을 찾아서 확률분포를 구성하는 것입니다.
앞의 식에서 K를 정해놓고 V(volumn)을 늘려가면서 결정하는 방식이 바로 Nearest-neighbour 입니다.
쉽게 설명하면 점 x가 있는데, 주위에 K/3가 빨간점이고 2K/3가 파란점이라면 x를 파란점으로 판단하는 것이죠.
이럴 경우, K가 바로 영역의 크기를 나타내게 되는데요..
K를 어떻게 고정하느냐에 따라서 판단 영역의 차이가 발생하게 됩니다.

x가 주어졌을 때, 클래스에 속할 확률을 구하는 것은 베이즈 정리를 잘 활용하면 되겠죠.
이 부분은 이전의 의사결정이론에서도 한번 다뤘기 때문에 해당 내용을 참고해 보기 바랍니다.
실제로 K값에 따른 확률분포를 구성하면 다음과 같습니다.