
 하둡 맵리듀스 Join 활용 퀴즈!!
하둡 맵리듀스 Join 활용 퀴즈!!
본 퀴즈는 University of California, San Diego의 Super Computer Center, Paul Rodriguez님의 강의에 포함된 내용이다. 해당 퀴즈에 대한 답은 올려놓지 않을 계획이므로 아래 내용을 잘 따라하고 직접 풀어보기 바란다. 하둡 맵리듀스 Join 활용 예제 를 참고하면 쉽게 구현할 수 있을 것이다. 아래 예제에 따라 데이터 파일을 생성하고 조인하는 맵리듀스를 파이썬으로 구현해 보도록 하자. 1. 퀴즈에 사용할 데이터 파일을 생성하는 다음 파이썬 소스를 make_join2data.py 파일로 저장한다. #!/usr/bin/env python import sys # ------------------------------------------------------..
 하둡 맵리듀스 Join 활용 예제
하둡 맵리듀스 Join 활용 예제
하둡 맵리듀스를 활용하다 보면 서로 다른 유형의 데이터 셋을 조인해야 하는 경우가 종종 있다. SQL에서 테이블간 조인을 생각해 보면 된다. Word Count 예제를 기반으로 맵리듀스의 조인을 고려해 보자. 특정 단어의 개수를 세는데 파일 하나는 전체 기간을 대상으로 하고, 다른 파일은 월별로 각 단어의 개수를 나타낸다고 해보자. 아래의 두 파일을 하나로 합쳐서 형태로 합쳐서 출력하는 부분을 하둡 맵리듀스로 구현해보는 것이다. join1_FileA.txt able,991 about,11 burger,15 actor,22 join1_FileB.txt Jan-01 able,5 Feb-02 about,3 Mar-03 about,8 Apr-04 able,13 Feb-22 actor,3 Feb-23 burger..
 하둡 스트리밍을 활용한 파이썬 word counting 예제~
하둡 스트리밍을 활용한 파이썬 word counting 예제~
하둡 스트리밍을 활용하면 맵리듀스 잡을 실행가능한 스크립트, 쉘 프로그래밍/파이썬/자바/R 등으로 처리할 수 있다. 하둡 스트리밍에 대해서는 Apache Hadoop Streaming을 참고하면 된다. 이번 강의에서는 기본 하둡 예제인 Word Count를 파이썬으로 구성한 후, 하둡 스트리밍으로 맵리듀스를 적용하는 예제를 살펴보기로 한다. 하둡 스트리밍 명령어는 다음과 같이 사용법을 확인할 수 있다. > hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar --help 1. 먼저 파이썬으로 맵 함수를 만들어 보자. WordCount에서 맵 함수는 파일의 각 라인별로 읽어서 공백으로 자른 다음, Key: 단어, Value: 1로 출력하면 된다. > ged..
 HDFS 명령어 테스트~
HDFS 명령어 테스트~
클라우데라의 QuickStartVM에서 HDFS 명령어를 테스트해보자. 하둡 파일 시스템의 전체 명령어는 하둡(Hadoop) 파일시스템 (HDFS) 명령어 정리~를 참고하기 바란다. 아래 내용은 University of California, San Diego의 Mahidhar Tatineni 교수 자료를 참고했다. 1. -ls 명령어로 현재 하둡 파일 시스템에 내용을 확인할 수 있다. VM에서는 /hbase, /solr 등의 디렉토리 구성을 볼 수 있다. > hdfs dfs -ls / 2. -mkdir을 사용하여 예제로 쓸 /user/test 디렉토리를 생성한다. > hdfs dfs -mkdir /user/test > hdfs dfs -ls /user/ 3. 리눅스의 dd 명령어를 통해 1GB의 대용량 ..
 Pig 두번째 예제 살펴보기~
Pig 두번째 예제 살펴보기~
passwd 파일에서 아이디, 이름, 홈디렉토리를 가져오는 피그 예제를 살펴봤다. 이번에는 하둡 완벽 가이드에 나왔던 연도별 최고 온도를 계산하는 예제를 살펴보기로 하자. 해당 예제에 대한 설명은 Hive & Pig - 하둡(Hadoop)의 맵리듀스를 보다 편하게~ 를 참고하기 바란다. 1. 먼저 예제로 사용할 sample.txt 파일을 만들어 보자. > vi sample.txt 2. 년도 온도 품질 순으로 탭을 공백으로 다음과 같이 입력하고 저장한다. 3. 생성한 sample.txt 파일을 하둡 파일 시스템의 /user/cloudera에 업로드하고 확인한다. > hdfs dfs -put sample.txt /user/cloudera > hdfs dfs -ls /user/cloudera 4. pig를 실..
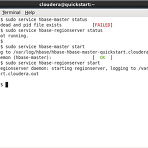 HBase 예제 살펴보기~
HBase 예제 살펴보기~
이번에는 클라우데라에 포함된 HBase에 대해서 살펴보도록 하자. HBase에 대해서는 하둡(Hadoop) 관련 기술 - 피그, 주키퍼, HBase에 대한 간략한 정리! 를 참고하기 바란다. HBase 서버 확인 먼저 HBase 서버가 동작 중인지 확인해 봐야 한다. HBase는 Master와 RegionServer가 모두 동작해야 하므로 다음 명령어로 상태를 확인하고 동작 중이 아닌 경우, start 명령어로 시작하면 된다. > sudo service hbase-master status > sudo service hbase-regionserver status > sudo service hbase-master start > sudo service hbase-regionserver start HBase 실..
 Hive 예제 살펴보기~
Hive 예제 살펴보기~
클라우데라의 QuickStartVM을 통해 하둡 어플리케이션을 살펴보고 있다. 이번에는 Hive를 beeline과 Hue를 통해서 간략하게 알아보자. Hive Beeline 예제 1. 터미널을 띄우고 /etc/passwd 파일을 HDFS의 /tmp 폴더에 넣는다. > hdfs dfs -put /etc/passwd /tmp/ > hdfs dfs -ls /tmp/ 2. Hive를 실행하기 위해 beeline을 실행한다. > beeline -u jdbc:hive2:// 3. beeline에서 userinfo 테이블을 생성하고, /tmp/passwd 파일을 읽어서 테이블에 저장한다. jdbc:hive2://>> CREATE TABLE userinfo ( uname STRING, pswd STRING, uid I..
 Pig 첫번째 예제 VM에서 실행하기~
Pig 첫번째 예제 VM에서 실행하기~
클라우데라의 QuickStartVM에서 피그 스크립트를 실행하는 것을 살펴보기로 한다. 피그(Pig)와 관련된 내용은 다음 글을 참고하기 바란다. 하둡(Hadoop) 관련 기술 - 피그, 주키퍼, HBase에 대한 간략한 정리! Hive & Pig - 하둡(Hadoop)의 맵리듀스를 보다 편하게~ 오늘 살펴볼 예제는 VM의 passwd 파일을 HDFS에 업로드하고, 해당 파일에서 사용자 아이디, 사용자 이름, 그리고 홈디렉토를 가져와서 결과를 저장하는 것이다. 다음 순서대로 따라해 보자. 1. /etc/passwd 파일을 HDFS의 /user/cloudera로 업로드한다. > hdfs dfs -put /etc/passwd /user/cloudera > hdfs dfs -ls /user/cloudera/p..
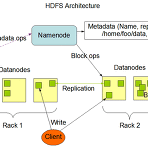 Hadoop 2.0 - HDFS2와 YARN
Hadoop 2.0 - HDFS2와 YARN
HDFS vs HDFS2 기존의 하둡 파일 시스템의 가장 큰 취약점은 바로 네임노드였다. 여러 개의 데이터 노드를 연결해서 데이터 노드에서 발생할 수 있는 하드웨어 오류에 대응할 수 있었지만, 네임 노드는 하나로 구성함으로써 위험에 노출되어 있던 것이 사실이다. HDFS2로 넘어가면서 네임노드에도 확장성을 위해 여러 개의 네임노드를 구성할 수 있도록 변경하였다. 그래서 네임 서버들을 구분하기 위한 여러 개의 네임스페이스를 도입하게 되었고, 네임 서버에 대한 고가용성도 확보할 수 있었다. 또한 여러 개의 네임 서버에서 데이터 노드를 관리하기 위해서 Block Pools 개념도 등장한다. 마찬가지로 하둡 1.0의 맵리듀스에서도 마스터 노드에 하나의 잡트래커를 사용했다. 잡트래커에서 스케쥴링, 모니터링, 실패..
 [QuickStartVM] 하둡 word counting 테스트
[QuickStartVM] 하둡 word counting 테스트
클라우데라의 QuickStart VM을 활용해서 하둡 맵리듀스를 처리하는 예제를 살펴보기로 하자. 만약 VM이 설치되어 있지 않다면, QuickStart VM 설치하기 글을 참고하기 바란다. 테스트할 예제는 가장 기본적인 WordCount 예제이다. 해당 소스에 대한 설명은 WordCount 맵리듀스 테스트 글을 살펴보기 바란다. Word Count 테스트 이제 QuickStart VM을 통해서 Word Count를 해보기로 하자. 1. VM에서 터미널을 열고 다음 명령어로 hadoop-mapreduce-examples.jar 파일이 있는 곳으로 이동하고 해당 파일을 확인한다. > cd /usr/lib/hadoop-mapreduce/ > ls *examples.jar 2. hadoop jar 명령어로 w..
- Total
- Today
- Yesterday
- 도서
- 하둡
- 구글
- r
- 마케팅
- 안드로이드
- HTML
- 디자인
- 아이폰
- 통계
- 빅데이터
- 클라우드
- SCORM
- XML
- 세미나
- 애플
- 맥
- 프로젝트
- fingra.ph
- ms
- mysql
- Hadoop
- 분석
- java
- 자바
- 모바일
- 웹
- 책
- 자바스크립트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |