
 nohup 명령어 활용하기
nohup 명령어 활용하기
터미널로 접속해서 명령어를 실행한 후, 해당 터미널을 종료해도 계속 명령어가 실행되도록 유지하고 싶을 때 nohup 명령어를 사용한다. 만약 mini.sh을 nohup으로 실행할 경우 다음과 같이 사용하면 된다. > nohup ./mini.sh &nohup: ignoring input and appending output to ‘nohup.out’ &는 백그라운드로 명령어를 실행하라는 것이다. 만약 &를 빼고 해서 실행했을 경우, Ctrl+Z를 눌러 백그라운드로 돌릴 수 있다. 그리고 nohup으로 실행할 경우, 화면에 출력될 내용이 기본적으로 nohup.out 파일로 리다이렉트 된다. 다음 명령어로 쉘 프로그래밍이 제대로 진행되는지 결과를 확인할 수 있다. > cat nohup.out 참고로 실행중인 ..
 IOPS (Input/Output Operation Per Second)에 대하여~
IOPS (Input/Output Operation Per Second)에 대하여~
IOPS는 단위 시간(1초) 동안 디스크로부터 Input/Output을 수행한 수치를 의미한다. 즉, 초당 입출력 횟수라 볼 수 있다. 기본적으로 HDD, SSD, SAN 같은 컴퓨터 저장장치를 벤치마크 하는 데 사용하는 성능 측정 단위이기도 하다. IOPS는 Iometer, IOzone, FIO 등 응용프로그램으로 측정할 수 있다고 한다. IOPS를 구할 수 있는 기본 수식은 다음과 같다. IOPS = 1000 / (Average Read Seek Time + (Maximum Rotational Latency / 2)) 디스크를 읽고 쓰기 위해서 "탐색 시간 + 회전 대기 시간"이 필요하다. 이런 평균 탐색 시간을 구하고, 회전 대기 시간은 최대 값을 구해서 2로 나누는 방식으로 평균 회전 대기시간을 ..
리눅스에서 SSH 사용시 암호 없이 로그인해서 처리해야 할 필요가 있을 때가 있다. Hadoop 설치에서도 각 서버들이 서로 접속할 수 있도록 SSH 설정을 해야 한다고 설명한 적이 있다. 그래서 암호 없이 ssh 로그인하는 부분을 간략하게 정리해 보려고 한다. 먼저 클라이언트에서 ssh-keygen으로 키를 생성해야 한다. # ssh-keygen -t rsa 그리고 .ssh/ 디렉토리에 생성된 id_rsa.pub 파일을 서버로 복사한다. 서버에서 파일명을 authorized_keys로 변경하고 퍼미션을 600으로 설정한다. # mv ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys# chmod 600 authorized_keys 이렇게 서버에 파일을 복사하고 authorized_..
 SSH 세션을 계속 유지하기 위한 설정
SSH 세션을 계속 유지하기 위한 설정
SSH를 사용하다보면 접속이 끊겨서 다시 연결해야 하는 경우가 종종 있다. 보안상의 이유로 계속 사용하지 않으면 접속 종료하기 때문이다. 개발 중 잠시 자리를 비우고 돌아왔을 때, SSH가 종료되어 있으면 귀찮기 마련이다. 리눅스에서 SSH 접속을 계속 유지하기 위한 설정에 대해서 한번 정리해 보기로 한다. 원격 서버 설정 SSH로 접속하는 원격 서버에서 설정을 하면 접속하는 클라이언트에 동일하게 적용할 수 있다. 원격 서버 설정은 SSH 데몬의 config 파일을 수정하면 된다. 1. /etc/ssh/sshd_config 파일을 연다. # vi /etc/ssh/sshd_config 2. sshd_config 파일에 다음과 같이 추가한다. ClientAliveInterval 30 ClientAliveCo..
 리눅스에서 at을 활용한 예약 작업 처리하기
리눅스에서 at을 활용한 예약 작업 처리하기
리눅스에서 미리 만들어진 스크립트를 예약된 시간에 실행하는 기능이 필요해서 at 명령어를 사용해 봤습니다. at 명령어와 작업 시간을 지정하고 난 후, 실행할 명령을 입력한 다음 Ctrl + D로 저장하면 됩니다. 예약된 작업의 확인은 atq로 할 수 있습니다. at을 실행하는 데몬은 atd로 /etc/init.d/atd 가 있습니다. 만약 실행되어 있지 않다면 다음과 같이 데몬을 실행할 수 있겠죠. # /etc/init.d/atd start 간략하게 정리해 봤습니다.
 자동 배치 처리를 위한 crontab 사용법
자동 배치 처리를 위한 crontab 사용법
리눅스와 같은 유닉스 계열에서는 주기적으로 자동 배치 처리를 하기 위해서 쉘 스크립트와 crontab을 사용합니다. 즉, 쉘 프로그램을 crontab에 등록된 시간에 자동으로 실행하도록 하는 것으로 서버 로그 정리, 통계/정산 등 배치 작업에 많이 사용하고 있습니다. 그럼 crontab에 등록하고 사용하는 방법에 대해서 한번 살펴보도록 하지요. 먼저 crontab의 도움말은 다음 그림과 같습니다. 생각보다 많은 옵션이 존재하지 않습니다. -l 이나 -e 정도의 옵션을 알고 시간 설정하는 방법을 이해하면 될 것 같습니다. crontab 리스트 확인하기 현재 서버에서 동작하고 있는 crontab을 확인하기 위해서는 -l 옵션을 사용합니다. > crontab -l 30 0 * * * /usr/local/min..
 리눅스에서 date 명령어 알아보기~
리눅스에서 date 명령어 알아보기~
리눅스에서 사용할 수 있는 date 명령어를 정리해 보도록 하겠습니다. date 명령어는 날짜와 관련된 처리를 할 수 있는데요. 날짜 출력이나 날짜 설정 등의 작업을 할 수 있습니다. 로그 파일 등을 처리하는 쉘 프로그래밍에서도 유용하게 사용할 수 있습니다. 날짜 포맷에 따라 출력하기 먼저 날짜 포맷으로 출력하는 부분을 살펴보도록 하지요. date라는 명령어를 입력해 보면 다음과 같이 나타납니다. > date Mon Aug 6 12:51:42 KST 2012 여기에 날짜 포맷으로 출력하기 위해 + 기호를 사용해봤습니다. > date +%Y-%m-%d 2012-08-06 년도-월-일의 순서대로 출력하도록 포맷을 지정한 것입니다. 이와 같이 지정할 수 있는 것은 다음과 같습니다. 내용을 살펴보면 왠만한 날짜..
리눅스에서 Java를 설치하기 위한 방법들은 예전 글에서도 한번 정리한 적이 있는데요. 이때는 Redhat 계열의 CentOS에서 세팅하는 것이어서 RPM 명령어로 설치하는 것을 설명했었습니다. 이번에는 Debian 계열인 우분투(Ubuntu)에서 APT 명령어로 설치하는 것을 정리해 보도록 하지요. APT-GET 사용법 우분투는 데비안을 기반으로 하고 있기 때문에 RPM이 아닌 apt-get으로 프로그램을 설치하게 됩니다. 한글입력기로 유명한 nabi 패키지를 가지고 apt-get 명령어에 대해서 한번 살펴보도록 하죠.. nabi 설치 : apt-get install nabi 제거하기 : apt-get --purge remove nabi 검색하기 : apt-cache search nabi 패키지 정보보..
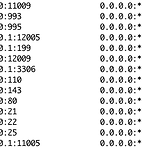 리눅스에서 현재 접속하고 있는 사용자 수 확인하기
리눅스에서 현재 접속하고 있는 사용자 수 확인하기
실제 접속한 사용자가 있을 때, 웹서버를 재시작하는 경우가 종종 있어서 현재 접속한 사용자가 있는지 확인하는 리눅스 명령어가 필요해 정리해 봤습니다. 결과부터 이야기 하면 명령어는 다음과 같습니다. netstat -an | grep :80 | grep ESTB | wc -l이 명령어를 alias를 적용해서 사용하면 바로 체크할 수 있습니다. 그럼 각각의 명령어를 한번 정리해보도록 하죠. netstat현재 시스템의 네트워크 상태를 알려주는 명령어 입니다. 프로토콜, Local Address, Foreign Address, 상태 등의 정보를 제공해 주는데요. 다양한 옵션으로 더 많은 정보를 볼 수도 있습니다. -a 모든 소켓 정보를 출력합니다. -n 호스트명 대신 숫자로 출력합니다. -p PID와 프로그램 ..
 아파치 로그를 쉽게 필터링 할 수 있는 프로그램 cronolog~
아파치 로그를 쉽게 필터링 할 수 있는 프로그램 cronolog~
아파치 로그를 분석하는 awstats에 대해서는 지난번에 블로깅을 한 적이 있습니다. 2011/08/20 - [프로그래밍/리눅스] - 웹로그 분석 프로그램 AWStats 활용 그런데 최근 로그 파일을 분석하려고 해보니 2달 정도 쌓이 로그가 6G 정도 되더라구요. (월별로 쌓도록 구성했어야 했는데.. 설정을 변경해야 겠네요. ㅠㅠ) awstats가 분석하다가 결국 out of memory라는 말을 남기고 그대로 종료해 버렸습니다. 그래서 로그 파일을 분할하는 프로그램을 찾아봤는데요. cronolog(http://cronolog.org/)라고 하는 프로그램이 있더군요. 원래는 아파치 로그가 쌓일때 월별, 날짜별로 저장하도록 필터를 쉽게 설정할 수 있는 프로그램이라고 합니다. 그런데 여기 실행파일을 보면 c..
- Total
- Today
- Yesterday
- 도서
- mysql
- 애플
- XML
- 맥
- 웹
- 책
- 분석
- 프로젝트
- 세미나
- 마케팅
- 구글
- 통계
- 아이폰
- 디자인
- 하둡
- 안드로이드
- ms
- 자바스크립트
- HTML
- r
- java
- Hadoop
- SCORM
- 클라우드
- 자바
- 모바일
- fingra.ph
- 빅데이터
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |