
 OpenCV 이미지 유사도 비교 #2 - 히스토그램 비교
OpenCV 이미지 유사도 비교 #2 - 히스토그램 비교
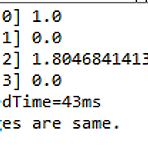
OpenCV를 활용한 이미지의 유사도 비교에서 먼저 피처 매칭을 살펴봤다. 오늘은 히스토그램 비교를 알아보도록 하자. 히스토그램은 매개변수에 따라 Correlation, Chi-square, Intersection, Bhattacharyya 각각의 결과값을 가질 수 있다. 그래서 중요한 부분이 각각의 결과값을 어떻게 해석하는 것이다. Correlation과 Intersection은 값이 클수록 유사한 것이고, Chi-square와 Bhattacharyya는 값이 작을수록 유사한 것으로 판단한다. Comparing Histogram 먼저 전체 소스를 살펴보면 다음과 같다. 마찬가지로 C로 구현되어 있는 Histogram 소스를 자바로 변환한 것이다. package kr.co.acronym; import j..
 OpenCV 이미지 유사도 비교 #1 - 피처 매칭
OpenCV 이미지 유사도 비교 #1 - 피처 매칭
OpenCV의 설치와 자바 프로그래밍 테스트를 살펴봤으니, 이제 이미지 유사도 비교를 해보도록 하자. OpenCV를 활용한 이미지의 유사도 비교는 히스토그램 비교, 템플릿 매칭, 피처 매칭의 세 가지 방법이 있다. 오늘은 이 중에서 피처 매칭(Feature Matching)을 알아보도록 하자. Feature Matching 먼저 전체 소스를 살펴보면 다음과 같다. 일반적으로 C로 구현되어 있는 Feature Matching 소스를 자바로 변환한 것이다. package kr.co.acronym; import org.opencv.core.Core; import org.opencv.core.CvType; import org.opencv.core.DMatch; import org.opencv.core.Mat; ..
 OpenCV 자바 이클립스에서의 프로그래밍 시작하기~
OpenCV 자바 이클립스에서의 프로그래밍 시작하기~
OpenCV를 자바 환경에 설정하는 것은 지난번에 살펴봤다. 이번에는 실제 자바 프로젝트에서 프로그래밍하는 방법을 알아보기로 하자. OpenCV 라이브러리를 자바프로젝트에 설정하기 먼저 일반적인 자바 프로젝트를 하나 생성한다. 여기에서는 "Mini"라는 이름의 프로젝트를 생성했다. 환경 설정을 위해 생성된 프로젝트의 "Properties"에 들어가서 좌측의 "Java Build Path"를 선택하고 상단의 "Libraries"를 클릭한 후, 우측의 "Add Library.."를 통해 앞서 설정한 OpenCV를 지정하면 된다. 이어서 "User Library"를 선택한 후, OpenCV-3.0.0을 지정하면 된다. 최종적으로 다음과 같이 라이브러리가 설정된 것을 확인할 수 있다. OpenCV 자바 프로그래..
 OpenCV 설치 및 자바 이클립스 환경 설정~
OpenCV 설치 및 자바 이클립스 환경 설정~
OpenCV는 2.4.4버전 이후로 자바를 지원하기 시작했다. OpenCV를 윈도우즈에 설정해서 이클립스 기반의 자바 프로젝트로 테스트를 해보도록 하자. OpenCV 3.0 설정 최신 버전의 OpenCV는 3.0으로 윈도우즈, 맥, 리눅스, 안드로이드, iOS등 다양한 운영체제를 지원한다. 우측의 OpenCV for Windows를 클릭하면, opencv-3.0.0.exe 파일을 다운로드한다. 이 파일은 압축 실행파일이라 별도의 설치를 하지 않고 압축만 풀게 된다. OpenCV의 폴더 구조와 자바 버전에서 사용할 jar파일의 위치를 빨간 테두리로 표시해봤다. 압축이 풀린 opencv 폴더를 c:\opencv로 복사하고 시스템 환경변수의 PATH에 다음 사항을 추가한다. C:\opencv\build\x86..
 OpenCV를 활용한 이미지 유사도 비교 방법~
OpenCV를 활용한 이미지 유사도 비교 방법~
OpenCV는 인텔이 개발한 오픈소스 컴퓨터비전 C 라이브러리이다. 실시간 이미지 프로세싱을 위한 라이브러리로 윈도우, 리눅스 등 여러 플랫폼에서 활용할 수 있다. 원래 C 언어로 되어 있지만 최근에는 Java 언어로도 적용할 수 있고, 안드로이드 및 아이폰과 같은 모바일 환경도 지원한다. 다양한 이미지 프로세싱 알고리즘을 지원하기 때문에 처음에는 두 이미지가 동일한지 비교하는 메소드 같은 것이 존재할 줄 알았다. 그러나 두 이미지의 동일성을 OpenCV로 비교하는 것은 생각보다 쉽지 않았다. 히스토그램 비교, 템플릿 매칭, 피처 매칭의 세 가지 방법이 있다고 하는데 각각의 방법으로 구현한 다음 많은 테스트를 통해 실제 어느 정도 값이 나오면 일치한다고 판단할지를 정해야 한다. 이 부분은 다음 번 글에서..
 F Measure - Precision과 Recall을 통합한 정확도 측정
F Measure - Precision과 Recall을 통합한 정확도 측정
동전을 10번 던져서 계속 앞면이 나왔다고 하면, 앞면이 나올 확률을 1이라고 할 수 있을까? 분명 동전을 던진 회수가 너무 적기 때문에 1이 아니라고 이야기할 것이다. 즉, 계속해서 반복했을 때도 동일하게 나오는지 체크하는 것이 필요하다. 그래서 일반적인 정확도(Precision) 뿐만 아니라 재현율(Recall)이 정보검색, 패턴인식, 기계학습에서 의미가 있는 것이다. 이러한 정확도와 재현율을 하나의 지표로 통합해서 정확성을 측정하는 방법들이 존재한다. F-Measure 정확성을 측정하는데 가장 많이 사용하는 F-Measure에 대해 살펴보기로 하자. F-Measure는 Precision과 Recall의 트레이드오프를 잘 통합하여 정확성을 한번에 나타내는 지표라 할 수 있다. 보통 가중치를 가진 조화..
 정확도와 재현율 (Precision and Recall)에 대하여~
정확도와 재현율 (Precision and Recall)에 대하여~
정보검색이나 패턴인식에서 정확도(Precision)과 재현율(Recall)이라는 용어를 자주 사용한다. 기계학습에서도 정확도와 재현율에 기반해서 예측의 정확성을 검증하기도 하므로 기본적인 개념을 살펴보도록 한다. 정보검색에서의 정확도와 재현율 만약 정보검색을 위해 100개의 문서를 색인한 "미니" 검색엔진이 있다고 가정해 보자. 여기에 "빅데이터"란 키워드로 검색을 했는데, 검색 결과로 20개의 문서가 나왔다. 20개의 문서 중 16개의 문서가 실제로 "빅데이터"와 관련된 문서였고, 전체 100개의 문서 중 "빅데이터"와 관련된 문서는 총 32개라고 하자. 이 경우, 정확도(precision)와 재현율(recall)은 어떻게 될까? 정확도는 검색 결과로 가져온 문서 중 실제 관련된 문서의 비율로 나타낸다..
 몬테카를로 시뮬레이션~
몬테카를로 시뮬레이션~
분석을 하면서 "몬테카를로 시뮬레이션"을 한번쯤은 들어봤을 것이다. 몬테카를로는 무작위 값을 활용하여 확률적으로 계산하는 알고리즘을 이야기한다. 이렇게 확률적으로 계산함으로써 원하는 수치의 확률적 분포를 구할 수 있게 된다. 이를 위해 많은 수의 실험을 바탕으로 한 통계를 이용해 확률적 분포를 알게 되므로, 이것을 바로 몬테카를로 시뮬레이션이라고 한다. 몬테카를로 시뮬레이션 개념 몬테카를로는 통계 자료가 많고 입력값의 분포가 고를수록 정밀하게 시뮬레이션 할 수 있다. 그래서 컴퓨터를 이용해 시뮬레이션을 주로 한다. 또한 이론적 배경이나 복잡한 수식으로 계산해야 하는 경우, 근사치를 계산하기 위해서도 몬테카를로를 많이 사용한다. 몬테카를로 시뮬레이션은 모나코의 유명한 도박 도시이름을 따서 만들었다고 한다...
 Nonparametric Method - 평균/분산을 모를때 확률분포를 만드는 방법
Nonparametric Method - 평균/분산을 모를때 확률분포를 만드는 방법
지금까지 살펴본 확률분포는 모두 평균이나 분산과 같은 매개변수들을 기반으로 확률분포를 정하게 됩니다. 예를 들어, 정규분포(Normal Distribution)에서는 평균과 분산을 알고서 확률분포를 구하게 되죠.. 그런데 만약 평균과 분산과 같은 매개변수를 모를 경우, 확률 분포를 어떻게 알 수 있을까요? 특히 정규분포와 달리 여러개의 봉으로 이루어진 데이터라면, 기존의 방식으로 확률 분포를 알수는 없을 겁니다. 이렇게 매개변수가 없을 때, 확률 분포를 구하는 방법을 Nonparamtric Method라고 합니다. (보통 비모수적 방법이라고 이야기 하는 것 같습니다.) Nonparametric Method는 보통 Histogram, Kernel Density, Nearest Neighbour 세가지가 있..
 Multinomial Variables - 다항 분포와 Dirichlet 분포에 대하여
Multinomial Variables - 다항 분포와 Dirichlet 분포에 대하여
Binary Variables에 이어 Multinomial에 대해서 정리해 보도록 하죠. Binary가 동전의 앞면/뒷면과 같은 경우를 이야기한다면, Multinomial은 주사위를 던지는 경우를 생각하면 될 것 같습니다. 즉 K=6의 상태를 가지고 있고, X3 = 1인 경우, 다음과 같이 나타낼 수 있습니다. 확률이므로 K=1부터 6까지의 X의 전체 합은 1이 되겠죠. 독립이므로 여러번 주사위를 던질때 확률은 다음과 같이 곱으로 계산할 수 있습니다. (k에 대한 평균이 파라미터로 주어졌을 때, Xk가 나올 확률을 의미합니다.) 이때, 파라미터로 사용하는 평균은 다음과 같은 조건을 가지고 있습니다. 이번에는 X1에서 Xn까지의 독립 관측에서의 데이터 셋을 D라고 할 때, 다음과 같은 likelihood ..
- Total
- Today
- Yesterday
- 세미나
- 클라우드
- HTML
- XML
- java
- 모바일
- 안드로이드
- ms
- 애플
- 통계
- 맥
- 아이폰
- 하둡
- 자바
- 디자인
- 자바스크립트
- 도서
- 책
- 빅데이터
- 프로젝트
- 웹
- 분석
- 구글
- Hadoop
- SCORM
- fingra.ph
- r
- 마케팅
- mysql
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |