
 R 시뮬레이션 - 랜덤 변수 샘플링
R 시뮬레이션 - 랜덤 변수 샘플링
R에서 시뮬레이션을 위해서 임의의 변수를 생성하는 경우가 종종 있다. 이번에는 다양한 랜덤 변수를 생성하는 방식을 정리해 보려고 한다. Sample 가장 일반적으로 임의의 수를 생성하는 함수는 sample() 이다. sample() 함수는 다음과 같이 범위를 지정해 주고 추출할 수의 개수를 지정하면 된다. 첫번째 예제는 1~10 사이의 임의의 수 4개를 추출한 것이다. 마지막 예제는 letters에 저장된 알파벳 26자 중에서 5개를 임의로 생성한 것이다. 만약 동일한 값이 중복해서 생성해도 된다면, 다음과 같이 replace = TRUE를 지정하면 된다. 그리고 다음 예제를 살펴보자. set.seed(1)를 사용하고 있는데, 잘 보면 set.seed(1)이 호출된 다음에 sample() 함수의 결과가 ..

 R의 split 활용
R의 split 활용
R의 apply 함수들을 살펴봤는데 이와 함께 사용할 수 있는 유용한 split() 함수에 대해서 알아보도록 하자. split split은 말 그대로 데이터를 나누는 함수이다. 벡터, 리스트, 데이터셋과 같은 객체를 지정된 팩터(factor)에 따라 분리하는 기능을 한다. split을 이해하기 위해서 먼저 데이터를 생성해보자. rnorm(10)을 이용해서 평균 0, 표준편차 1인 정규분포의 수 10개를 생성하고, runif(10)를 이용해서 균등분포를 갖는 10개의 수를 만들고, rnorm(10, 1)을 통해 평균 1, 표준편차 1인 정규분포의 임의의 숫자 10개를 만든다. 그리고 gl(3, 10)을 통해 3개의 팩터(factor)1, 2, 3에 해당하는 각각의 수 10개를 만든다. 이후 split(x,..
 R의 apply, tapply의 활용법을 알아보자~
R의 apply, tapply의 활용법을 알아보자~
지난번엔 R의 lapply, sapply, vapply를 살펴봤다. 이어서 다른 종류의 apply를 알아보도록 하자. apply lapply와 sapply는 모두 리스트를 입력으로 받아서 각 리스트에 함수를 적용한다고 했다. 만약 리스트가 아닌 행렬(matrix)을 입력으로 넣으면 어떻게 될까? rnorm()으로 평균 0, 표준편차가 1인 정규분포를 갖는 20x10 행렬을 만들었다. 그리고 lapply로 평균을 구해보니, 결과가 무려 200개의 리스트가 나온다. 즉, 행렬의 각각의 요소를 리스트의 개별 요소로 보고 처리한 것이다. 보통 행렬에서는 각각의 행이나 열에 대해 함수를 적용하는 것이 필요하다. 이런 경우에 apply를 사용하면 된다. apply 함수의 두번째 인자로 1을 넣으면 행(row)에 대..
 R의 lapply, sapply, vapply를 이해하자~
R의 lapply, sapply, vapply를 이해하자~
R에는 lapply, sapply, vapply, apply, tapply등 다양한 apply 함수들이 존재한다. 데이터 분석에서 "Split-Apply-Combine" 이라는 전략을 구현한 것이 바로 apply이다. 즉, 데이터셋을 나누어서 각 조각들을 만들고, 각각의 조각에 특정 함수를 적용하고, 결과를 합쳐서 제공한다는 것이다. lapply 먼저 lapply부터 살펴보자. lapply의 l은 리스트를 나타낸다. 즉, 입력으로 리스트를 받아서 결과로 리스트를 제공한다는 것이다. lapply를 테스트하기 위해 먼저 리스트를 만들어 보자. rnorm은 정규 분포를 따르는 수를 만드는 것으로, rnorm(10)은 기본값으로 평균 0, 표준편차 1인 정규분포를 갖는 10개의 수를 만든다. 리스트의 각 항목,..
 [R 퀴즈#3] R 프로그래밍 테스트 - Air Pollution 파트 3
[R 퀴즈#3] R 프로그래밍 테스트 - Air Pollution 파트 3
존스 홉킨스 대학의 로저 펜(Roger, D. Peng) 교수의 R 프로그래밍 강좌의 프로그래밍 테스트를 한글로 옮겨본다. R 프로그래밍을 배우는 사람들은 한번씩 테스트 해보기 바란다. 데이터 본 예제에서 사용하는 데이터를 다음 링크에서 다운로드 한다. 문제 - 오염된 값 사이의 상관관계 계산하기 마지막으로 지정된 파일을 읽어서 오염된 값 sulfate와 nitrate의 상관관계를 계산하는 함수를 만들어 보자. 단, 각 파일(모니터링 아이디)별로 sulfate와 nitrate의 값이 모두 존재하는 경우의 수가 매개변수로 지정된 임계치(threshold)보다 큰 값만 대상으로 한다. 결과값으로 임계치(threshold) 조건을 만족하는 모니터링 아이디의 상관관계 값의 벡터를 리턴한다. 만약 모든 모니터링 ..
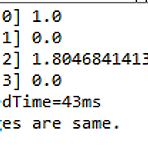 OpenCV 이미지 유사도 비교 #2 - 히스토그램 비교
OpenCV 이미지 유사도 비교 #2 - 히스토그램 비교
OpenCV를 활용한 이미지의 유사도 비교에서 먼저 피처 매칭을 살펴봤다. 오늘은 히스토그램 비교를 알아보도록 하자. 히스토그램은 매개변수에 따라 Correlation, Chi-square, Intersection, Bhattacharyya 각각의 결과값을 가질 수 있다. 그래서 중요한 부분이 각각의 결과값을 어떻게 해석하는 것이다. Correlation과 Intersection은 값이 클수록 유사한 것이고, Chi-square와 Bhattacharyya는 값이 작을수록 유사한 것으로 판단한다. Comparing Histogram 먼저 전체 소스를 살펴보면 다음과 같다. 마찬가지로 C로 구현되어 있는 Histogram 소스를 자바로 변환한 것이다. package kr.co.acronym; import j..
 [R 퀴즈#2] R 프로그래밍 테스트 - Air Pollution 파트 2
[R 퀴즈#2] R 프로그래밍 테스트 - Air Pollution 파트 2
존스 홉킨스 대학의 로저 펜(Roger, D. Peng) 교수의 R 프로그래밍 강좌의 프로그래밍 테스트를 한글로 옮겨본다. R 프로그래밍을 배우는 사람들은 한번씩 테스트 해보기 바란다. 데이터 데이터는 다음 링크에서 다운로드 하면 된다. 문제 - 오염된 값을 모두 측정한 경우의 수 계산 지정된 디렉토리의 파일들을 읽어서, 각 파일 내에 "sulfate"와 "nitrait"값이 모두 측정된 경우의 수를 계산하는 함수를 작성한다. 함수의 결과값으로 반드시 데이터 프레임을 리턴하도록 한다. 첫번째 칼럼은 파일 이름, 즉 모니터링 아이디(ID) 값으로 하고, 두번째 칼럼은 오염된 값을 모두 측정한 수로 한다. 함수의 프로토타입은 다음과 같다. complete
 OpenCV 이미지 유사도 비교 #1 - 피처 매칭
OpenCV 이미지 유사도 비교 #1 - 피처 매칭
OpenCV의 설치와 자바 프로그래밍 테스트를 살펴봤으니, 이제 이미지 유사도 비교를 해보도록 하자. OpenCV를 활용한 이미지의 유사도 비교는 히스토그램 비교, 템플릿 매칭, 피처 매칭의 세 가지 방법이 있다. 오늘은 이 중에서 피처 매칭(Feature Matching)을 알아보도록 하자. Feature Matching 먼저 전체 소스를 살펴보면 다음과 같다. 일반적으로 C로 구현되어 있는 Feature Matching 소스를 자바로 변환한 것이다. package kr.co.acronym; import org.opencv.core.Core; import org.opencv.core.CvType; import org.opencv.core.DMatch; import org.opencv.core.Mat; ..
 [R 퀴즈#1] R 프로그래밍 테스트 - Air Pollution 파트 1
[R 퀴즈#1] R 프로그래밍 테스트 - Air Pollution 파트 1
존스 홉킨스 대학의 로저 펜(Roger, D. Peng) 교수의 R 프로그래밍 강좌의 프로그래밍 테스트를 한글로 옮겨본다. R 프로그래밍을 배우는 사람들은 한번씩 테스트 해보기 바란다. 데이터 본 예제에서 사용하는 데이터를 다음 링크에서 다운로드 한다. 압축을 풀면 332개의 CSV 파일이 specdata 폴더에 존재한다. 미국의 332개 지역의 공기 오염 상태를 모니터링하는 데이터로서, 각각의 파일에 모니터링 지역의 ID 값을 가지고 있고 그 ID 값으로 파일 이름을 사용하고 있다. 각 파일의 내부에 포함된 내용은 다음과 같다. Date: the date of the observation in YYYY-MM-DD format (year-month-day)sulfate: the level of sulfa..
- Total
- Today
- Yesterday
- r
- XML
- 세미나
- 통계
- 분석
- ms
- mysql
- SCORM
- 모바일
- 애플
- 하둡
- 디자인
- 프로젝트
- 웹
- Hadoop
- 안드로이드
- 도서
- HTML
- 자바
- 자바스크립트
- 맥
- 구글
- 빅데이터
- 마케팅
- 아이폰
- java
- fingra.ph
- 책
- 클라우드
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |